前言
在go web开发中,很多时候会选用一款web框架,随着项目功能增加,接口也越来越多,一款好的路由框架能很方便的帮助我们管理与维护繁多的接口地址。
抽空看了下httprouter的源码(gin框架内置了定制的httprouter),代码量很少(去掉空白和注释也就600行左右),本次就的源码记录下,以留备忘。
httprouter版本:1.3.0
使用
使用很简单,如:
1
2
3
4
router := httprouter.New()
router.GET("/", Index)
流程
原理
httprouter使用了前缀树来存储路由和其对应的处理函数。
httprouter为每个http方法均创建了一颗前缀树。
1
2
3
4
5
6
7
8
9
10
11
12
type node struct {
path string // 路径
wildChild bool // 路径是否有通配符(:或*)
nType nodeType // 节点类型,static(默认),root,param,catchAll中的一种,对应值为0,1,2,3
maxParams uint8 // 当前节点及其子节点最大param数量
priority uint32 // 优先级
indices string // children的索引(孩子节点的第一个字母)
children []*node // 孩子节点
handle Handle // 路由处理函数
}
假如我们有下面这几个路径(GET方法):
/search/
/support
/blog/:post/
/blog/:post/:name
/files/*filepath
则创建的前缀树如下:
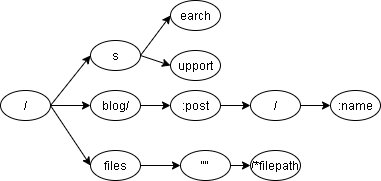
插入
插入代码为func (n *node) addRoute(path string, handle Handle)。
插入即为前缀树的插入操作,从根节点开始,查找树是否有相同前缀,对无共同前缀的部分进行插入操作,在这个操作中,原来的节点非共同前缀部分会作为子节点。
要注意的是,插入分为有参数(有:或*符号)和无参数两类
1.path为最大能利用的公共前缀,当为叶子节点时,则为除去路径前缀的剩余部分(无参数)
2.如果有参数的路径,在上一步会进行额外操作,把参数部分裂开作为一个单独节点。如:/blog/:name/:id/,即使其为叶子节点,会把:name和:id作为单独节点
3.如果有通配符(*),则只能为最后一个节点。
查找
查找代码func (n *node) getValue(path string)
查找时同样分为有参数和无参数两类
1.对于无参数的路径,直接根据node.path匹配,根据node.indices进入下一节点顺着树查找即可。
2.对于有参数的路径,区分参数(:符号)和通配符(*),拿到路径对应的参数,也比较简单。
总结
1.httprouter使用前缀树来复用空间
2.代码简洁易懂
3.支持路径传参和通配
4.有优先级,保证匹配的确定性
参考: